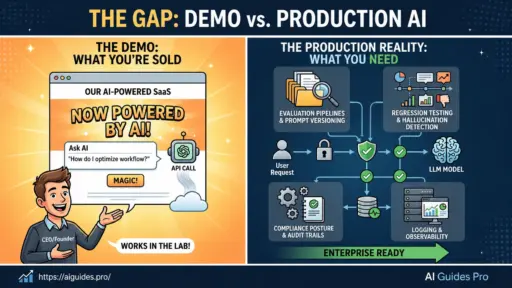
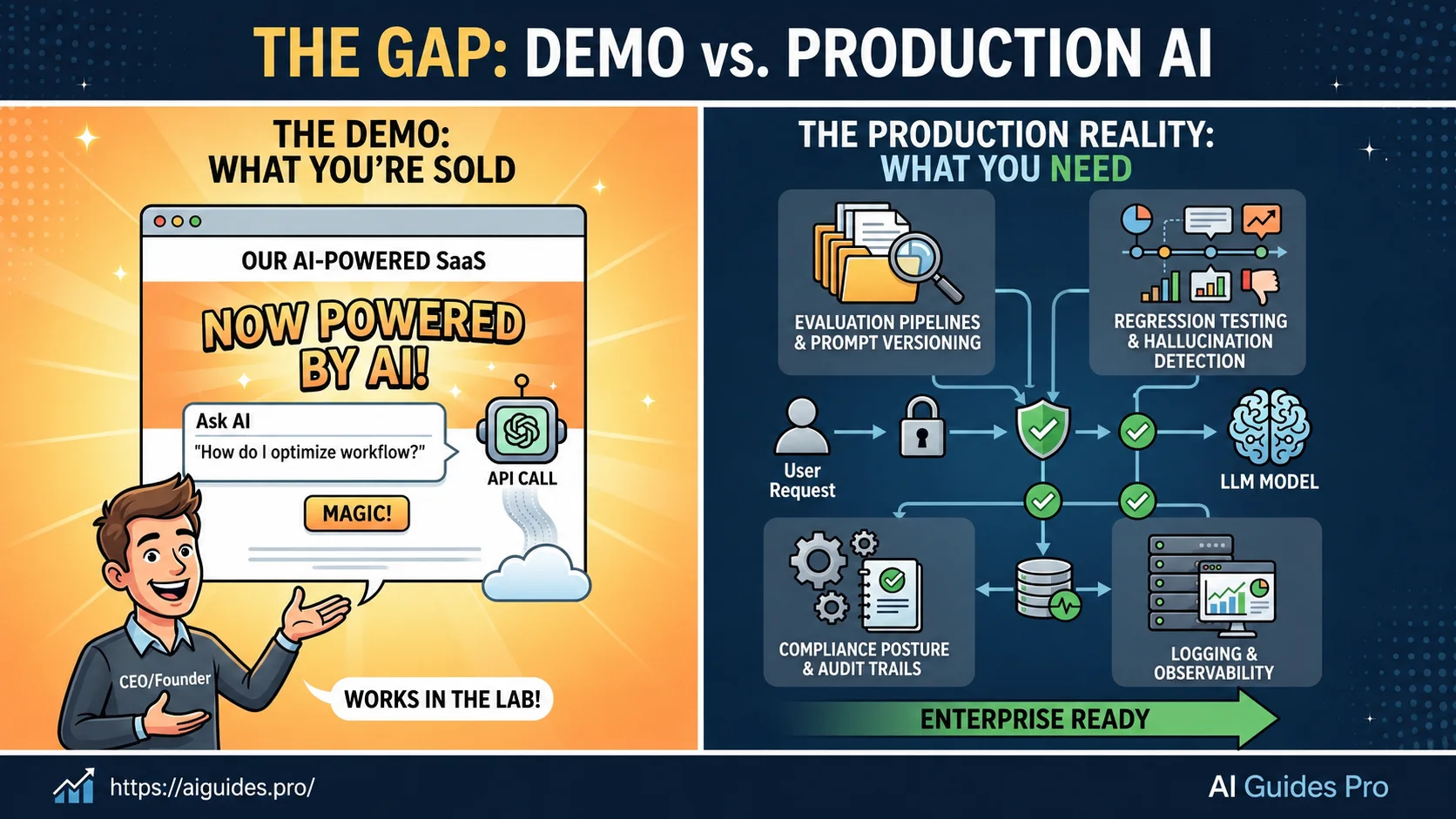
Every SaaS company added “AI-powered” to their homepage in 2026. Most of them are telling the truth, technically. They made an API call to OpenAI, wrapped it in a clean UI, and shipped it. The demo works. The investors are impressed. The sales deck looks great.
Then they hit 10,000 users. A compliance team asks for an audit trail. The LLM provider quietly updates the model and the output changes. An edge case produces a hallucinated answer that reaches a customer in a regulated industry.
The gap between “demo-grade AI” and “production-grade AI” opens up fast, and it is not closed by more prompt engineering.
The difference is infrastructure: evaluation pipelines, prompt versioning, regression testing, and reliability engineering. Most teams skip these because they feel like overhead. They are not overhead. They are the only reason enterprise clients will sign.
Demo Vs. Production: What Actually Breaks At Scale
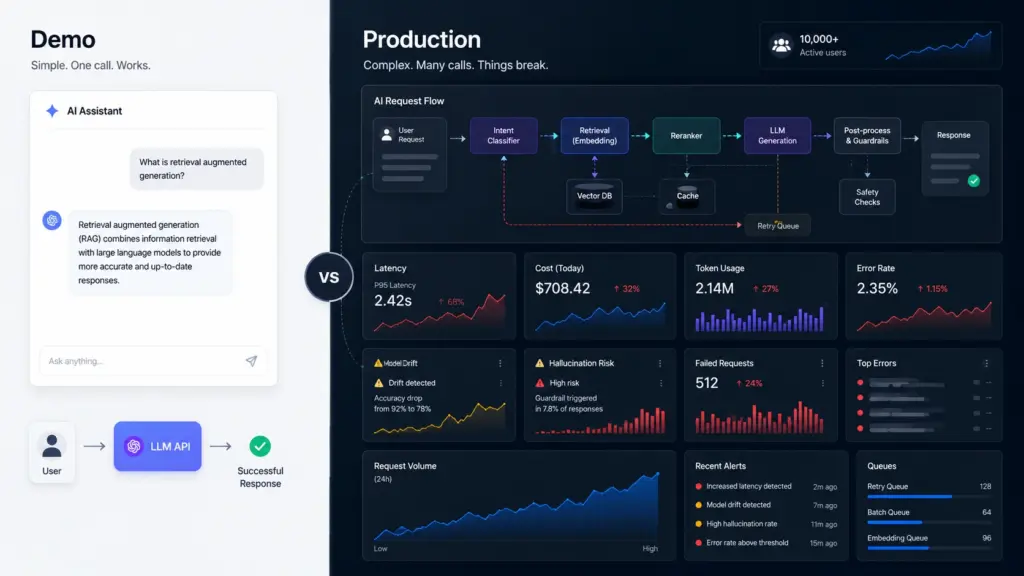
A single API call to a foundation model is straightforward. It either returns a useful response or it does not. At 100 users, you see every failure and fix it manually. At 10,000 users, you see nothing unless you built observability first.
What breaks at scale:
- Latency variance compounds when every user interaction chains multiple LLM calls
- Token cost grows faster than revenue if nobody is tracking it
- Model drift happens when the provider updates the underlying model without changing the version string
- Edge case volume increases with user diversity, and edge cases are where hallucinations live
None of these problems are unique to AI. They are standard distributed systems problems. The difference is that with a conventional API, a wrong answer is a bug. With an LLM, a wrong answer looks like a confident, well-formatted paragraph.
Prompt Versioning: Why You Need It Before Your First Enterprise Client
Most teams treat prompts like comments. They live in a config file, get updated when something breaks, and nobody tracks what changed or when.
That is fine until an enterprise client asks: “What prompt was used to generate this output six months ago?”
Prompt versioning is not complicated. It is the same discipline applied to code:
- Every prompt has a version identifier
- Changes are committed and reviewed like code changes
- Deployed versions are logged alongside every model output
- Rollback is possible without touching application code
The harder version of this is prompt regression testing: when you change a prompt, you run the new version against a held-out set of historical inputs and compare outputs. You are not checking if the output is “good,” you are checking if it changed in ways you did not intend.
This matters most when the prompt drives a consequential decision, which is exactly the use case enterprise clients are paying for.
Regression Testing For LLM Outputs: What It Looks Like In Practice
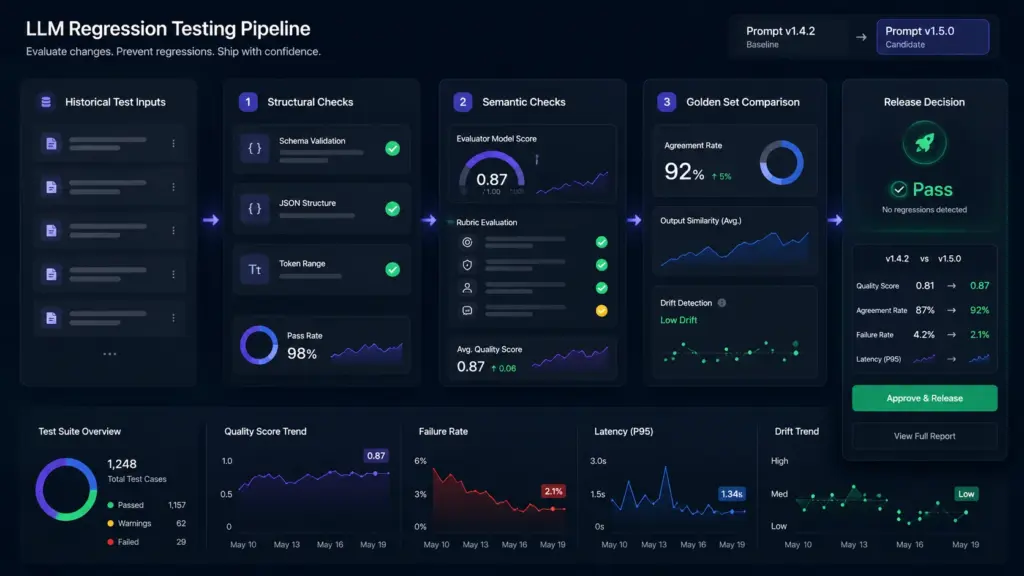
Unit testing a deterministic function is simple. LLM output is not deterministic and not binary. A response is not just “correct” or “incorrect,” it sits somewhere on a spectrum of relevance, accuracy, and tone.
That does not make testing impossible. It makes it more deliberate.
A practical regression suite for LLM outputs has three layers:
Structural checks are deterministic. Does the output conform to the expected schema? Is a JSON field present? Does the response stay within a token range? These run fast and catch the obvious failures.
Semantic checks use an evaluator model, often a separate LLM, to score the output against a rubric. “Does this response correctly answer the question? Does it avoid stating X?” This is not perfect but it is scalable.
Golden set comparison measures how often new outputs agree with a curated set of known-good responses on the same inputs. Drift in agreement rate signals a regression before users report it.
Teams that build this before they need it catch model provider updates, prompt changes gone wrong, and latency/quality tradeoffs during infrastructure changes. Teams that skip it find out about regressions from customers.
Audit Trails For Regulated Industries
SOC2, HIPAA, and FCA compliance share a common requirement: you must be able to reconstruct what happened, when, and why. An LLM integration without logging is not compliant. It is also not auditable.
A minimal audit trail for a production AI feature includes:
- Input hash or full input, depending on data sensitivity
- Model identifier and version
- Prompt identifier and version
- Output, or a hash if output is PII-adjacent
- Timestamp and user context
Confidence Or Evaluation Score If Applicable
This data is not expensive to store. It is expensive to reconstruct after the fact if you did not plan for it. A regulated client asking for audit trail documentation three months after go-live is not a solvable problem if the logs do not exist.
The more interesting implication is that teams that build proper logging discover they also have a training dataset. Every logged input-output pair, evaluated for quality, is a fine-tuning candidate. The infrastructure investment compounds.
The 12 To 18 Month Window
Foundation model capabilities are converging. The gap between GPT-4 class models from different providers narrowed significantly in 2026 and will continue to narrow. Competing on model quality is not a durable strategy.
The durable advantage is in the infrastructure layer: evaluation, reliability, compliance posture, and the institutional knowledge embedded in versioned prompts and regression suites built over time. This is not a six-month project. It takes 12 to 18 months to build and it accretes value with every production incident you catch before the customer does.
The companies that skip this step because it feels like overhead are betting that their competitors are also skipping it. Some of them are right. The ones who are wrong will find out when an enterprise deal closes on the company with the compliance documentation ready.
The Real Question
The question is not whether your AI feature works. Most of them work in demos.
The question is whether your AI infrastructure is ready for the enterprise client who wants a SOC2 review, needs an audit trail for every model output, and will require you to explain what changed when your accuracy metrics shift.
That client is not three years away. In most regulated verticals, they are next quarter.
Conclusion
Most “AI-powered” products are one API call wrapped in a UI. That works until scale, compliance, or a model update exposes the gap. Production-grade AI requires prompt versioning, regression testing, and audit trails, not better prompts.
The first-mover advantage in regulated verticals is not about model quality. It is about the infrastructure built before the enterprise client asks for it. That window is 12 to 18 months, and it is already open.




Add your first comment to this post